SD-WAN Headend Design Guidelines
![]() For supported software information, click here.
For supported software information, click here.
This article provides architectural and deployment guidelines for the Versa Networks headend components. The headend consists of a Versa Analytics cluster, a Versa Director, and a Versa Controller.
Design Considerations for Headend Architecture
A typical Versa SD-WAN headend architecture is fully resilient, providing geographical redundancy. When you deploy the headend in a public cloud, you deploy it in different availability zones. For these deployments, the infrastructure must provide the capability for interconnectivity among the headend components.
The SD-WAN headend topology has the following components:
- Northbound segment, for management traffic
- Southbound segment, for control traffic
- Service VNF router to interconnect data centers
The following figure illustrates the headend components, which shows a topology that has headend components in two geographically separated data centers.

Administrators and other OSS systems use the northbound network to access the Versa Director, Analytics GUI, and REST APIs. The northbound network is also used to maintain synchronization between Versa Directors in a high availability cluster. Controller nodes require the northbound network to connect to Versa Director over the out-of-band (eth0) interface so that the Versa Director can provision the Controller nodes.
The southbound network, or control segment, connects to the SD-WAN overlay through the Controller nodes. Because the Director and Analytics nodes are hosts and not routers, the topology requires an additional router to provide a redundant connection to both Controller nodes. A dynamic routing protocol (either OSPF or BGP) must be enabled on this router to provide accurate overlay IP prefix reachability status, and BFD must be enabled towards the service VNF device in the data center. This additional router can be an existing router in the data center network, or it can be a VOS edge device managed by Versa Director.
The solution assumes reachability between the data center networks over the Director northbound operations support system (OSS) network. If the control network service router experiences an outage, the Director node can be accessible using the northbound network, and the administrator can gracefully fail over to the standby Director node.
Note: It is not mandatory to always have the Controller nodes connect to all transport domains. Technically, the SD-WAN network can function if an SD-WAN branch device is connected to the Controller node over just one underlay. However, from a resiliency point of view, it is recommended that the Controller node connect directly to all the transport domains that you use.
Note: The Director northbound OSS network must be separate from the control network to avoid the possibility that a split-brain state arises between the Director nodes. In a split-brain scenario, both Director nodes are up but network reachability between them is lost. The results is that both Director nodes assume that they are the active nodes.
If internet access is enabled to the Versa Director then you must secure the northbound traffic with appropriate security. Where users are able to access Versa Director directly from the internet such as the cloud-hosted Versa Directors, you must use a third dedicated interface into a DMZ. This allows separation between the link used for Director Sync and the user internet access to the Director.
The following figure shows a simple single data center deployment that is not geographically dispersed and in which service VNF routers are not required. This topology uses flat Layer 2 LANs for both the northbound and control networks, and it uses VRRP in the control LAN for gateway redundancy. However, this design is not suitable for creating Layer 3 security zones at the headend. If security is required, you must configure firewalls in bridge mode.

Headend Deployment Options
You can deploy the typical headend architectures shown above as host OSs on physical hardware, which is called a bare-metal deployment. You can also deploy these headend architectures in a virtualized architecture, for which Versa Networks supports ESXi and KVM, and the AWS, Azure, and Google Cloud Platform public clouds.
Deploying the headend on bare-metal hardware provides better performance and scalability, typically, 20 to 30 percent over a virtualized architecture. However, deploying on physical hardware has hardware dependencies. For example, not all server hardware, such as special RAID controllers, is supported.
For both bare-metal and virtualized deployments, it is important to follow the hardware requirements described in Hardware and Software Requirements for Headend.
Firewall Dependencies for Headend Deployment in a Data Center
When you implement the headend in an existing data center, several protocols and functions are required to connect to the data center. You must follow the requirements for connectivity, reachability, and security. For more information on firewall requirements, see Firewall Requirements.
Best Practices for Hardening the Headend
If you deploy Versa Directors that are exposed to the internet so that external users can access them, you must apply common IT hardening practices. This includes installing Ubuntu OS patches, installing official certificates (Versa Networks software ships with self-signed certificates), and changing the default passwords. Note that you must use the OS patches provided by Versa and not install OS patches directly from Ubuntu.
For more information, see the following articles:
Versa Analytics Deployment Options
The minimum recommended Versa Analytics deployment for full redundancy requires a cluster of four Analytics nodes, as illustrated in the figure below. This design provides active-active high availability (HA), with two nodes having the Search personality and two nodes having the Analytics personality.
Redundancy is achieved by replicating the data between one or more nodes of the cluster. Network latency must be low to optimize storage and query performance. This is because there is a large amount of data movement between the nodes of the cluster. Therefore, it is recommended that you allocate the nodes of the same cluster in the same data center, or at least within the same availability zone. Note that synchronization of the Cassandra database requires less than 10 milliseconds of latency between the nodes in the same cluster.
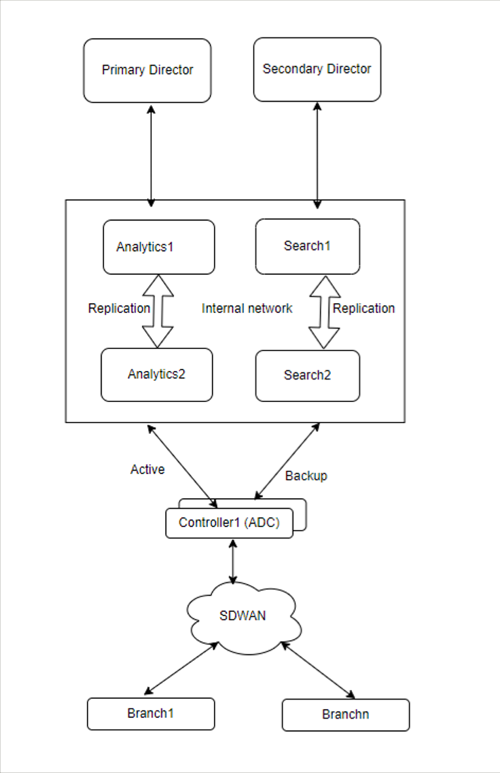
Recommended Production Analytics Deployment
To provide geographical resilience and for disaster recovery, you can add a second Versa Analytics cluster. You can set one cluster as a primary and the other as a secondary in the following redundant configurations.
Analytics Cluster Redundancy Options
You can configure a primary and secondary cluster in active-active or active-standby mode, or configure the secondary cluster for log redundancy only. We recommend that primary and secondary clusters run in separate datacenters. We do not recommend you separate the nodes a single cluster across multiple regions due to latency and performance issues. Running separate clusters per region helps manage these clusters independently and avoid downtime for storing and retrieving data during maintenance and node failures.
You can configure pairs of Analytics clusters in the following modes:
- Full Redundancy in Active-Active Mode—In this configuration, primary and secondary clusters have identical numbers of analytics, search, and log forwarder nodes. VOS devices are configured to send logs to both these independent clusters simultaneously. For detailed information about configuring clusters in active-active mode, see Configure a Secondary Cluster for Log Collection.
- Advantages:
-
Highly available.
-
The Analytics application can access all historic data from the secondary cluster when the primary cluster is down.
-
-
Limitations:
-
Running the entire database on a secondary cluster increases costs and operational complexity.
-
There is no cluster-to-cluster synchronization. If the primary cluster goes down, data may be retrieved from secondary cluster. However, when the primary cluster comes back up, there is no automatic synchronization of the data that the secondary cluster received during the downtime.
-
-
Sample Topology: A sample topology used for both active-active and active-standby modes is illustrated in the figure below. Note that although the topology is identical for the two modes, the software configuration differs for Controllers and VOS devices (branches).

- Advantages:
- Full Redundancy in Active-Standby Mode—In this configuration, primary and secondary clusters have identical number of analytics, search, and log forwarder nodes. VOS devices are configured to send one copy of the logs to Controllers. ADC load balancers on the Controllers are configured to send logs to only the primary cluster when all its Analytics nodes are up. When Analytics nodes are down, the load balancers automatically send logs to the Analytics cluster in the secondary data center. For information about configuring clusters in active-standby mode, see Configure a Secondary Cluster for Log Collection.
- Advantages:
- The Analytics application can access data from the secondary cluster when the primary cluster is down. In this mode, only data collected during the primary cluster down time is displayed.
-
Limitations:
-
Running the entire database on a secondary cluster increases costs and operational complexity.
-
The secondary cluster does not have data collected before the primary cluster went down.
-
When primary cluster operation resumes, you must switch between the clusters to get the consolidated data.
-
-
Topology: The topology for active-standby mode is identical to active-active mode.
- Advantages:
-
Log Redundancy Mode—In this configuration, the secondary cluster has only the log forwarders running. You configure ADC load balancers on Controllers to automatically forward logs to a secondary datacenter when all the nodes of the primary datacenter are down. The log forwarders in the secondary datacenter receive the logs and archive them. When the primary datacenter comes back up, you can run a cron script on the secondary log forwarders to transfer and populate the logs back to the primary Analytics cluster. Analytics nodes include a cluster synchronization tool to assist in the log transfer. For more information, see Cluster Synchronization Tool in What's New in Release 20.2.
-
Advantages:
-
No need to run the full Analytics cluster in the secondary datacenter and keep it in sync with the primary cluster in anticipation of the datacenter going down.
-
Saves on costs, without losing any data.
-
-
Limitations:
-
Until the primary cluster comes back up, Versa Analytics reports are not visible.
-
-
Sample Topology:

-
Role of the Log Forwarder
The Versa Operating SystemTM (VOSTM) edge devices generate logs destined for the Analytics database. These logs are carried in an IPFIX template and are delivered to the log forwarder. The log forwarder removes the IPFIX template overhead and stores the logs in clear text on log collector disk. The Analytics database servers can then access the logs from the log forwarder. Optionally, logs can be forwarded in syslog format to third-party log forwarders.
The log forwarder function is part of the Versa Analytics node. It can run on analytics or search nodes or on standalone log forwarder nodes, where a separate VM or server is dedicated to this role. For larger deployments, especially for deployments with 1000 or more branches, it is recommended that you separate the log forwarder function, because it provides better scalability for the Analytics platform. When the log forwarder runs on a separate device, you typically deploy it south of the analytics or search nodes, as shown in the following figure.

Best Practices for Versa Analytics Sizing
The scaling of a Versa Analytics cluster is driven by the logging configuration for the individual features enabled on VOS edge devices. Most features include an optional logging configuration to log events related to a specific rule or profile. The number of features for which you enable logging and the volume of logs that each feature generates has a direct impact on the sizing and scalability of the Versa Analytics cluster.
Versa Analytics has two distinct database personalities, Analytics node and Search node. The Analytics node delivers the data for most of the dashboards shown in the Analytics GUI. These data are aggregated data, and the data aggregation is enabled by default. Therefore, the dashboards are populated without configuration on the VOS edge devices. Analytics node scaling is determined by granularity of the reported data, which is usually set between 5 and 15 minutes. The topology also affects the scaling of the Dashboard feature. A full-mesh topology with multiple underlays generates more SLA logging messages compared to a hub-spoke topology with a single underlay. This is because SLA monitoring between branches in the underlay contributes significantly to the log volume as it reports SLA measurements to the Analytics node.
The primary tasks of the Search node are to store logging and event data, and to drive the log sections and log tables on the Dashboard. These functions are heavily utilized, because every event in the network triggers a log entry on the Search node. In a minimal default configuration, the only information that is logged to the search nodes are the alarm logs. The sizing of the search node depends on the following:
- Number of features enabled with logging
- Logging data volume and log rate
- Retention period of logged data
- Packet capture—You should enable packet capture and traffic monitoring only for traffic related to specific troubleshooting. Packet captures are not stored in the database, but rather as stored as PCAP files. If these files are not processed correctly, they can quickly fill up the disk space.
Feature such as firewall logging and traffic monitor logging (Netflow) have a significant impact on the overall scaling of the Analytics cluster. Therefore, it is recommended that you avoid creating wildcard logging rules. In response to an increases analytics load, you can scale both the Analytics and Search nodes horizontally. Versa Networks has a calculator tool that can help you size an Analytics cluster based on the information described in the next section.
Best Practices for Headend Design
A stable and fault-tolerant solution requires proper design of the headend. A proper design factors in the expected utilization in order to dimension the compute resources so that they can be horizontally scaled out when required. The headend design must be well thought out high availability design, to ensure that there is no single point of failures. Finally, the headend must be secured and hardened to avoid possible security vulnerabilities.
It is recommended that you consider the following when deploying a Versa Networks headend:
- Ensure that you configure DNS on the Director and Analytics nodes. DNS is used for operations such as downloading security packs (SPacks) an, on Analytics devices, for reverse lookup.
- Ensure that you configure NTP and synchronize it across all nodes in the SD-WAN network. It is recommended that you configure all nodes to be in the same time zone, to make log correlation between various components practical.
- Perform platform hardening procedures such as signed SSL certificates, password hardening, and SSL banners for CLI access.
- Ensure that you have installed the latest OS security pack (OS SPack) on all components and that you have installed the latest SPack on the Director node
- Ensure that the appropriate ports on any intermediate firewalls are open.
For more information, see the following articles:
For assistance with the design and validation of the headend before you move it into production, contact Versa Networks Professional Services.
Supported Software Information
Releases 20.2 and later support all content described in this article.